
Open Sora 发布!开源的高效复现类 Sora 视频生成方案
不久前 OpenAI Sora 的发布可以说是震惊了世界,但是奈何目前 OpenAI 还未将 Sora 开放公测,但在昨天,我们却等来了 Open Sora 1.0 的发布,这是 Colossal-AI 团队的一个完全开源的视频生成项目,致力于高效制作高质量视频,并使所有人都能使用其模型、工具和内容的计划。 通过采用开源原则,Open-Sora 不仅实现了先进视频生成技术的低成本普及,还提供了一个精简且用户友好的方案,简化了视频制作的复杂性。
模型训练报告
以下是 Colossal-AI 团队提供的模型训练报告:
为了降低计算成本,我们希望利用现有的 VAE 模型。 Sora 使用时空 VAE 来减少时间维度。然而目前还没有开源的高质量时空 VAE 模型。 MAGVIT 的4x4x4 VAE 不是开源的,而 VideoGPT 的 2x4x4 VAE 在我们的实验中质量较低。因此,我们决定在第一个版本中使用 2D VAE(来自 Stability-AI)。
视频训练涉及大量的 token。考虑 24fps 1 分钟视频,我们有 1440 帧。通过 VAE 下采样 4 倍和补丁大小下采样 2 倍,我们有 1440x1024≈1.5M 令牌。完全关注 150 万个代币会导致巨大的计算成本。因此,我们使用时空注意力来降低 Latte 之后的成本。
如图所示,我们在 STDiT 中的每个空间注意力之后插入一个时间注意力(ST 代表空间-时间)。这与 Latte 论文中的变体 3 类似。然而,我们不控制这些变体的类似数量的参数。虽然 Latte 的论文声称他们的变体比变体 3 更好,但我们对 16x256x256 视频的实验表明,在相同的迭代次数下,性能排名为:DiT(完整)> STDiT(顺序)> STDiT(并行)≈ Latte。因此,出于效率考虑,我们选择STDiT(顺序)。此处提供了速度基准。
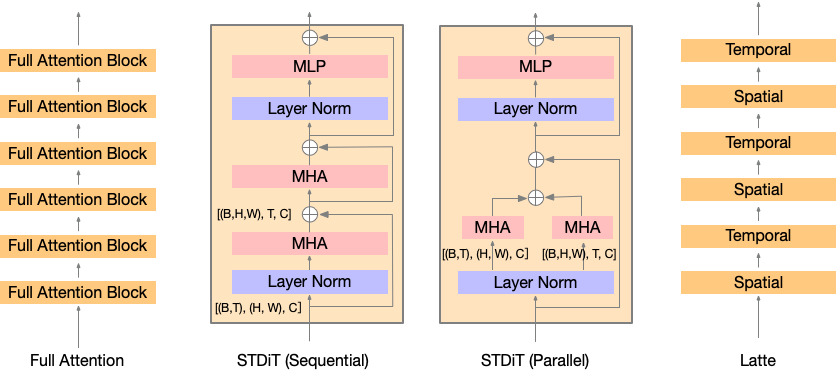
为了专注于视频生成,我们希望基于强大的图像生成模型来训练模型。 PixArt-α 是一种经过有效训练的高质量图像生成模型,具有T5条件DiT结构。我们用 PixArt-α 初始化模型,并将插入时间注意力的投影层初始化为零。这种初始化保留了模型在开始时生成图像的能力,而 Latte 的架构则不能。插入的 attention 使参数数量从580M增加到724M。
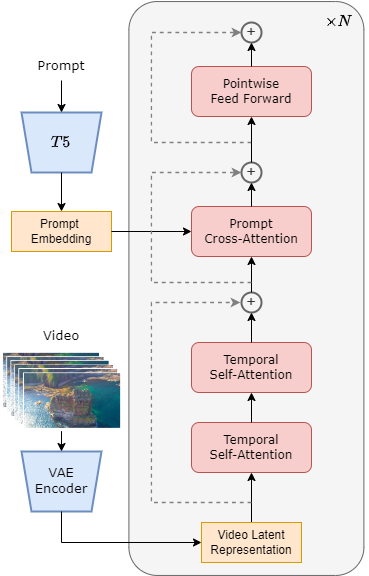
借鉴 PixArt-α 和 Stable Video Diffusion 的成功经验,我们还采用渐进式训练策略:在 366K 预训练数据集上使用 16x256x256,然后在 20K 数据集上使用 16x256x256、16x512x512 和 64x512x512。通过缩放位置嵌入,该策略大大降低了计算成本。
我们还尝试在 DiT 中使用 3D 补丁嵌入器。然而,在时间维度上进行 2 倍下采样,生成的视频质量较低。因此,我们在下一个版本中将下采样留给时间 VAE。目前,我们在 16 帧训练中每 3 帧采样一次,在 64 帧训练中每 2 帧采样一次。
我们发现数据的数量和质量对生成视频的质量有很大的影响,甚至比模型架构和训练策略还要大。此时,我们只准备了 HD-VG-130M 的第一个分割(366K 视频剪辑)。这些视频的质量参差不齐,而且字幕也不太准确。因此,我们进一步从提供免费许可视频的 Pexels 收集了 20k 个相对高质量的视频。我们使用 LLaVA(一种图像字幕模型)来标记视频,其中包含三个帧和一个设计好的提示。通过精心设计的提示,LLaVA 可以生成高质量的字幕。

随着我们更加重视数据的质量,我们准备在下一个版本中收集更多数据并构建视频预处理管道。
最新成果展示
以下是经过压缩的视频 gif 动图以及简化的提示词:

森林地区宁静的夜景。 该视频是一段延时视频,捕捉从白天到黑夜的过渡,以湖泊和森林作为恒定的背景。

翱翔的无人机镜头捕捉到了海岸悬崖的雄伟美景,水轻轻地拍打着岩石底部和悬崖顶部的绿色植物。

瀑布从悬崖上倾泻而下,注入宁静的湖泊,景色雄伟壮观。以相机角度提供了瀑布的鸟瞰图。

夜晚繁华的城市街道,充满了汽车前灯的光芒和路灯的氛围光。

向日葵田充满活力的美丽。向日葵排列整齐,营造出秩序感和对称感。

宁静的水下场景,海龟在珊瑚礁中游动。乌龟,有着绿棕色的壳。
项目开源地址:https://github.com/hpcaitech/Open-Sora
团队表示 Open-Sora 项目目前处在早期阶段,并将持续更新。